UTF-8/ UNICODE/ UTF-32/ BIG5 讀書心得
緣起
閱讀Joel On Software終於搞懂電腦文字編碼,也可以閱讀原文;讀完整理腦袋記憶

我本來的認知
我其實只會ASCII code,用C語言大概看下表就差不多了,每個字1byte;另外中文字BIG5需要2bytes;UNICODE每個字2byte,notepad++看過一些長得很像,不大清楚差異的東西
- UTF-32
- UTF-8
- UCS-2 little
- UCS-2 big

閱讀後,我的理解,不保證正確....
- UNICODE專案經過多年努力(吵架),最後誕生出一張共同的碼位表(Code Point):包括17個平面文字平面,每個平面包括65536個字;程式設計師會用0x00_0000 ~ 0x10_FFFF來描述;這張表足以容納全世界所有文字,甚至把表情符號都標準化
- 表示0x10_FFFF需要3byte,電腦喜歡2/4/8這種2的整數倍的東西,所以UTF-32/ UCS-4標準代表每個字4byte表示;這樣很浪費記憶體,但是很有效
- unicode我的認知每個字元2byte,應該是整體碼位0x00_0000 ~ 0x00_FFFF這個區域;這個標準叫UCS-16/ UCS-2;假設這兩個字元叫A/B,順序是AB還是BA,也就延伸兩個標準 (little/ big-endian);電腦處理UCS-2開銷還ok,英文字元開銷從1byte變成2byte,中文字維持不變
如果是軟體的API,資料型別是wchar_t,代表每個字用2byte表示;沒意外的話,軟體裡用wchar_t處理unicode應該是簡單有效率的
這表示電腦只能處理65536字,超出去了勢必代表資料丟掉;我猜常用的case都沒問題,不過需要跟全世界做生意,處理世界各地的地址,那這題就得小心處理了 - 如(3),UTF-8把Code Point用可變長度編碼,規則如下圖,幾個觀察
- 原先ASCII code的區域,0-127,還是只要1byte;表示英文和數字很有效率
- 第一個byte的MSB是0/110/1110/11110,這樣軟體可以很容易辨識開始;byte2/3/4的開頭必定是10,錯誤容易偵測;我猜中文字應該會大規模落在2~3bytes
- 這個編碼標準不用處理little/big endian這種麻煩事
- 在UNICODE專案成熟後,以BIG5為例,可以這樣理解頁碼(code page)
- 大家同意一個共同的編碼標準,表示全世界所有文字,最多16*65536個
- 中文世界的BIG5碼,從裡面挑出想支援的中文字;他可能會挑點常見的日文,表格符號;但是大概不會挑阿拉伯語的字
- 每個挑出來的字,從0x0000 ~ 0xFFFF挑一個數值編碼;這樣開啟檔案時,就能正確的解析所有字;存擋時,也能正確的寫入
- 在這個模型中,Python讀檔後,用"decode"解析成UCS2並且在內部處理;最後用"encode"編碼回BIG5,這樣的邏輯就很清楚了
- 軟體的實作
- 具體在軟體內部的表示,大概可以用wchar_t來代表大多數情況會出現的字;這樣的記憶體開銷還算可以接受
- 存擋的時候,使用者可以存各種type,可以是UTF-8,也可以是BIG5,簡體中文選GB2312
- 開啟檔案,不知道編碼的前提,可以檢視檔案每個byte的統計特性,比如BIG5/ GB2312應該會呈現不同的樣子。這讓軟體能自行判定文件的編碼,而不用使用者指定編碼格式
- 這一切都做得太自動,太完美,平常人都沒感覺

後記
平日的開發不牽涉到人類世界的複雜度;所以我的知識水平停留在ASCII code沒有進展
後記2
在PTT寫文章最大的好處是,會有專家幫忙補足想不通的點:UTF-16的Surrogate Pair

這東西的概念是這樣
- UNICODE 0xD800 ~ 0xDFFF大家講好不放東西;所以出現這種字元必定有詐!一般狀態是2byte代表一個字,這種狀態變成4byte代表一個字;很多地方都有類似的招數
- 要把UNICODE的U+10000 ~ U+10FFFF編進去,先把數值扣掉0x10000,看看他在16bit定址範圍外的offset多少,這裡的值域是0xFFFFF, 20bit
然後用這樣的規則編碼
byte0 = offset[19:10] + 0xD800
byte1 = offset[9:0] + 0xDC00 - 這種編碼結構好處是self-synchronization,因為開頭和結尾的值域固定下來了,如果中間有小錯誤也能偵測出來
- 缺點就LIB解析時,還有些額外的邏輯要弄,還真的有點麻煩;不過比起用4byte字串的開銷相比,應該勉勉強強能接受;反正現在電腦效能過剩,小事啦!

後記3
在ptt寫文章真的很讚,有更多高手給予回應
- 推 Dracarys: 再看完這兩篇就打通任督二脈了 11/08 09:13
- → Dracarys: https://tonsky.me/blog/emoji/ 11/08 09:13
- → Dracarys: https://tonsky.me/blog/unicode/ 11/08 09:13
原來Joel的文章刊出至今已經過了20年,UTF-8也真實的統治了世界;這篇文章仔細的論述UTF-32並不會讓世界變得簡單(每個字32bit),因為有Extended grapheme cluster存在

下面這個例子實在是傳神,原來e帶上一撇,這東西本身是兩個CODE-POINT組成;或是A上面多帶一個圈,可以是U+00C5或是U+0041 U+030A;真是一團混亂

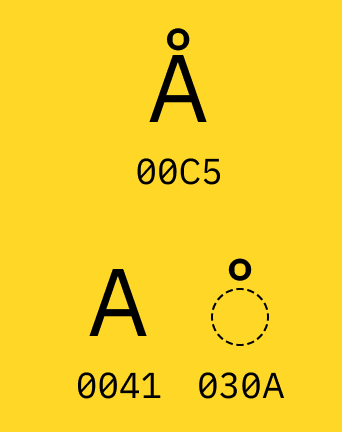
從C語言字串搭配ASCII看世界的我,覺得每個byte代表一個字元;所謂的strcmp()就是byte-by-byte做處理,這些的處理都很直覺;但是引入UNICODE之後,事情的複雜度就遠超想像了!常見的strlen()跟strcmp()都要考慮人類文字本身的複雜性
所以文章倒是說得很明白:處理UNICODE字串,用LIBRARY就對了,不要覺得他內部是UCS2之類的東西,讓專業的LIB幫忙;下次在Python處理UNICODE文字,要理解這些東西本質很複雜,所以才產生這麼多奇怪的用法,他已經不是C語言字串加上ASCII code那種東西了
REFERENCE
- Joel on software, unicode
- ptt的好文章
- 大五碼BIG5
- The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 (Still No Excuses!)



留言